SQL(Structured Query Language) 语言。
关系型数据库使用 SQL(Structured Query Language) 语言,每个 SQL 句子叫做 SQL Query 或 SQL Statement。我们可以用 CLI 指令或 GUI 软件,用 SQL 语言对数据库进行查询和操作。SQL 分成 DDL 和 DML 两种,都是用分号 ; 结尾。下面我们分别介绍,最后稍微引入一点高级用法。
Data Definition(定义) Language - DDL
告诉数据库去定义前面说的 Schema。
每家方法不太一样,建议会用 GUI 即可。PostgreSQL 和 MySQL 都是数据库服务器,可以管理很多数据库(例如你可以架很多 Rails 网站,但只需一个数据库服务器,里面建立不同数据库)。
建立数据库时,请注意选择编码(Encoding)。PostgrSQL 可用 utf8,MySQL 可用 utf8mb4(mb4就是most bytes 4的意思,专门用来兼容四字节的unicode)。
以下主要用 SQLite3 举例。
新建
建立数据库档案
在 Terminal 输入 sqlite3 your_db_name.db 就会打开(或产生)一个 数据库。(MySQL: mysql -u root -p,PostgreSQL: psql <database_name>。)
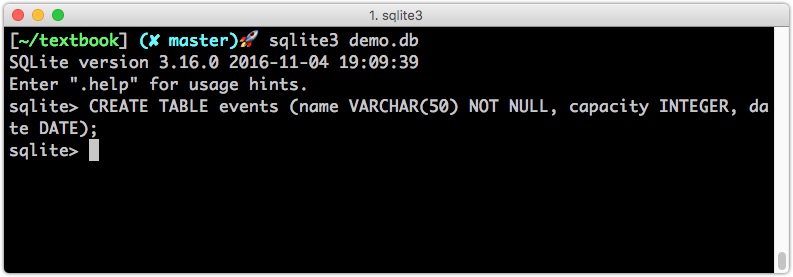
建立 Table
1 | # 建立 events 表,并新增三个字段 `name`, `capacity` 和 `date`。默认是字段允许 NULL,除非加上 NOT NULL。 |
可以用 SQLite3 的 GUI DB Browser for SQLite 打开 demo.db 档案:
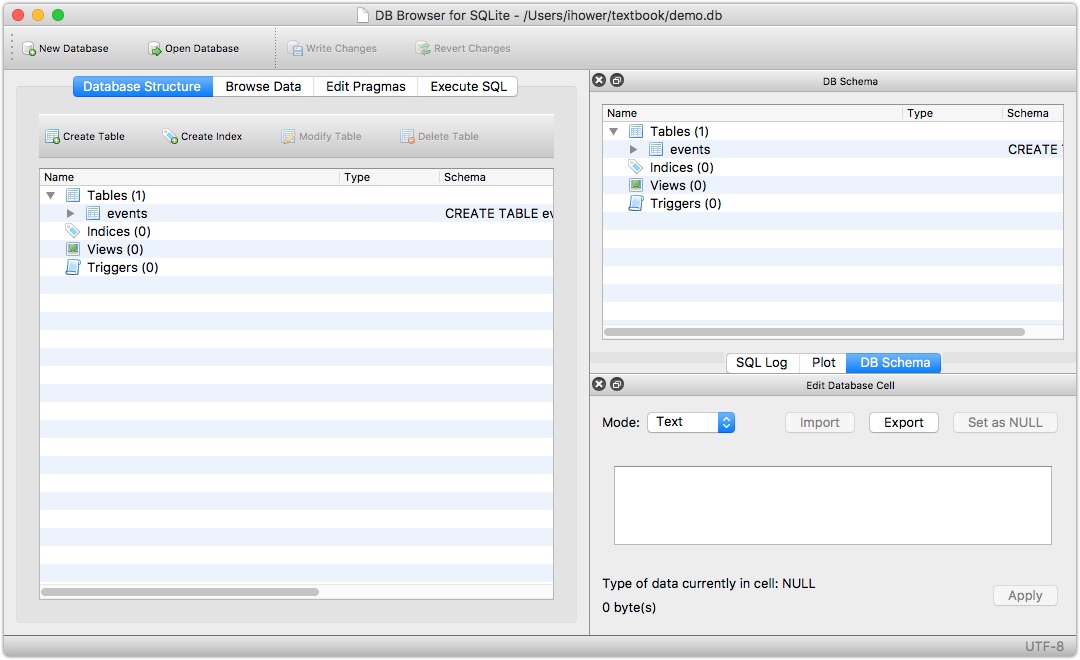
用 GUI 进行 Schame 操作比较简单,在 Rails 统一都用 Migrations 机制来变更 Schema。
修改
- Table 重命名:如
ALTER TABLE persons RENAME TO people; - 新增字段:如
ALTER TABLE people ADD COLUMN status VARCHAR(50); - 修改和移除字段:SQLite3 不支持,需新建一个 table 后把资料复制过去
删除
Table 删除: DROP TABLE IF EXISTS people;
通常不会让终端使用者动态新建 table 或修改 schema。数据库的 Schema 像是程序的一部分,代码会依赖于 Schema 设计。另外也有效能的考量,变更 Schema 操作很耗时,特别是数据很大的情况下,修改 Schema 会锁住整个 Table 从而影响网站正常运行。
Migration 机制
数据库 Schema 不是一成不变的,会随着软件变更升级也需要修改。因此,一些软件会实现一种叫做 Migration 的功能(如 Rails Migration),通过 Schema Migration 记录当前 schema 版本。开机时会检查当前程序版本和数据库版本是否相同,不同则执行 Migration 更新 schema。这些 Migration 代码也会放进版本控制系统 Git 里面,这样整个团队的开发者或不同服务器都可利用 Migration 来一致管理 Schame。
Data Manipulation(操作) Language - DML
操作数据的 SQL 就是 DML,即 CRUD(Create, Read, Update, Delete)。
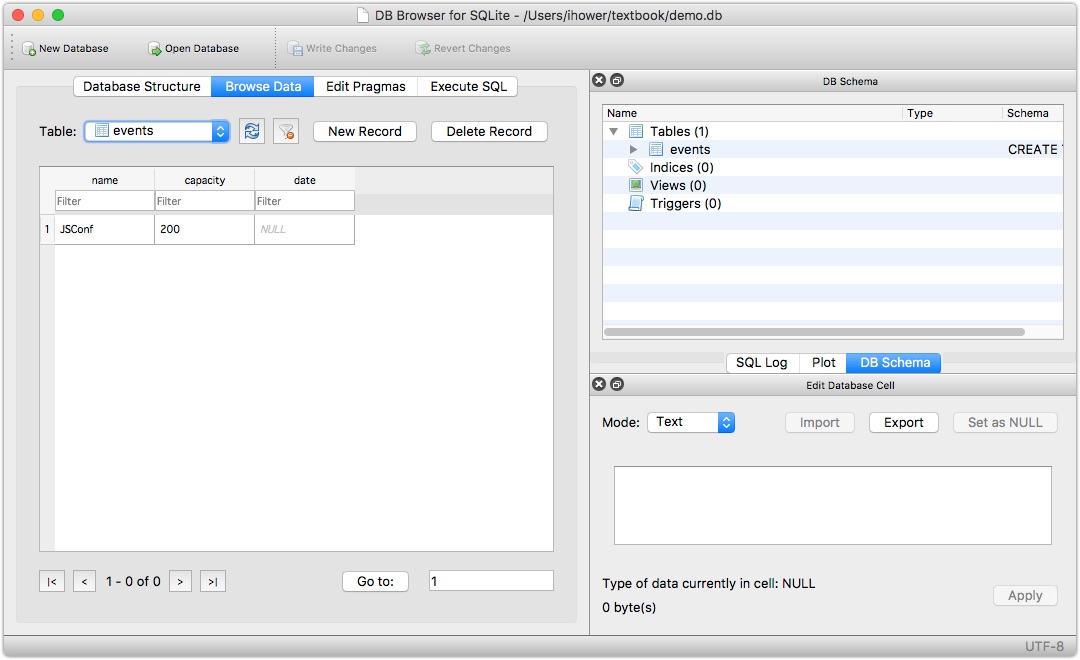
新增
1 | # 新增数据 capacity=200 name="JSConf" 到 events 这个 table 中 |
对应的 Rails 语法是:
1 | Event.create( :capacity => 200, :name => "JSConf") |
在 GUI 的视窗中查看:
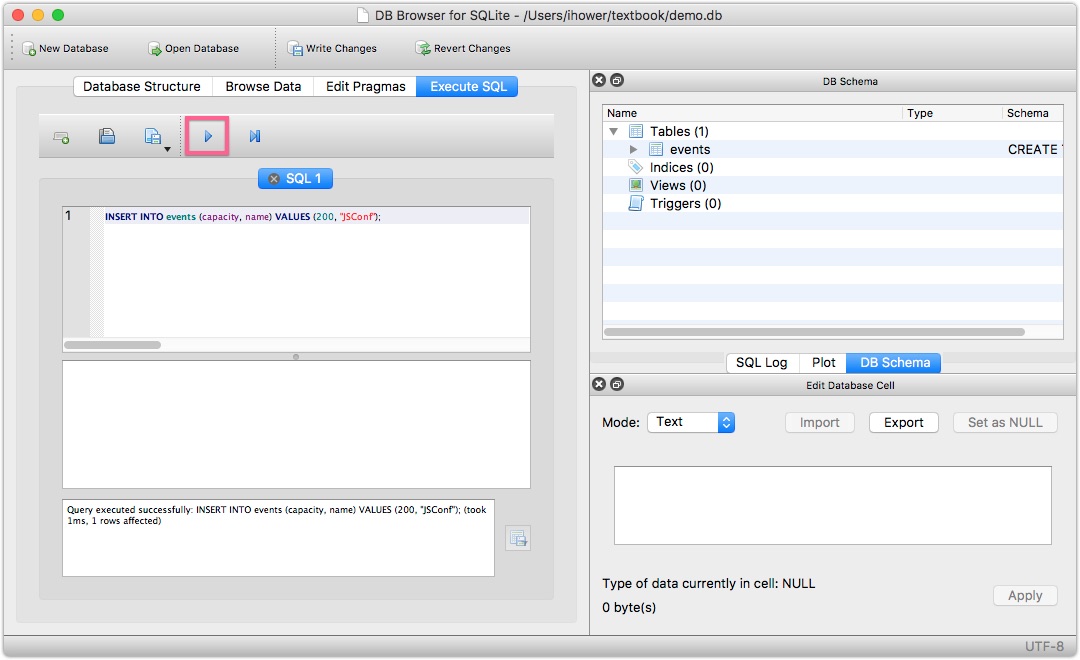
插入多笔数据 INSERT INTO events (capacity, name) VALUES (300, "COSCUP"), (300, "OSDC.TW");
也可以在 GUI 的视窗中,练习输入 SQL 句:
查询
一般查找
1 | # 取出全部 events 资料 |
特殊的,比如:
查找有哪些 tables 和 columns
各家语法不一样:
SQLite3:.tables和.schema tablename
MySQL:show tables和describe tablename
PostgreSQL:\dt和\d tablename
这些查询在 Rails 启动后,也会帮我们做。你可以在 rails console 中对 model 执行 columns 方法,例如
Event.columns 就会取出这个表有哪些字段。
特殊条件查找
1 | SELECT * FROM events WHERE date = '2015-03-15'; |
小心大小写。不同数据库默认不同。MySQL 不分大小写(case insensitive),PostgreSQL 区分大小写(case sensitive)。
Indexes 索引
上面的 WHERE、ORDER 条件字段最好都要加上数据库索引(Index),如果没有索引的话,是 O(n) 的效率(这里又叫作 Full Table Scan,需要扫描整个表),数据库越大越慢。如果有索引,是 O(logn),在数据量大的情况二者相差非常大。
模糊搜寻 LIKE 查询都会变成 Full Table Scan。( Rails 中 ransack gem 是用 LIKE 语法,几万笔数据还能接受,再大的数据量就需要用另外的 Full-Text Searching 引擎了,例如 ElasticSearch 。 )
加索引的 SQL 语法:
1 | # 加索引 |
将字段设成 unique 跟设成 unique index 是一样的。
当然也不是所有字段通通都加上索引就好了,因为加索引会让写入数据变慢(因为要建立索引,也会增加储存空间),但是查询时会加快。
修改
1 | # 修改 events table 的所有数据把 capacity 改成 10 |
在 Rails 中,比较常见只修改一笔数据,如:1
2
3
4
5@event = Event.find(123)
@event.update( :capacity => 200)
# 对应的 SQL:
SELECT * FROM events WHERE id = 123;
UPDATE events SET capacity=200 WHERE id=123;
删除
1 | # 全部删除 |
在 Rails 中,比较常见只删除一笔数据,如:1
2
3
4
5@event = Event.find(123)
@event.destroy
# 对应的 SQL:
SELECT * FROM events WHERE id = 123;
DELETE FROM events WHERE id = 123;
高级操作
Joins
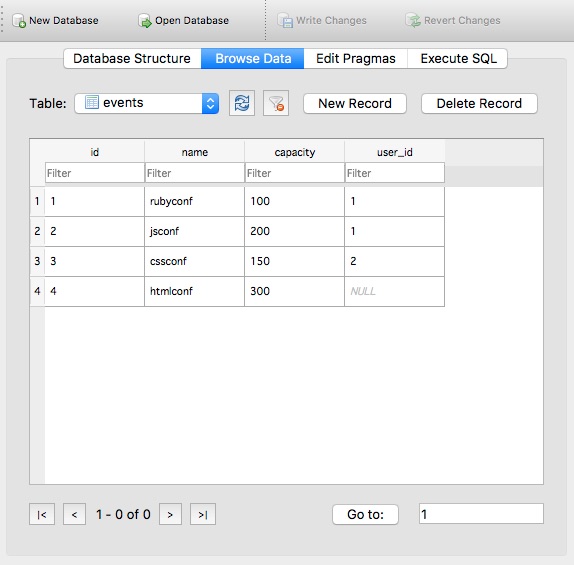
SQL 查询厉害在于,可以同时关联(Join)多张表来进行复杂查询。我们用个例子说明。先准备数据:
1 | # 建立 user 一对多 events。执行 `sqlite3 test.db`,并输入以下 SQL: |
建立好的数据库如下图:
跨 Tables 进行 Join 查询,常用的有 Inner Join 和 Outer Join 两种:
Inner Join (合并两 tables,接不起来就不要)
1 | # 取出所有活动,以及该活动参与者资料: |
结果如图:
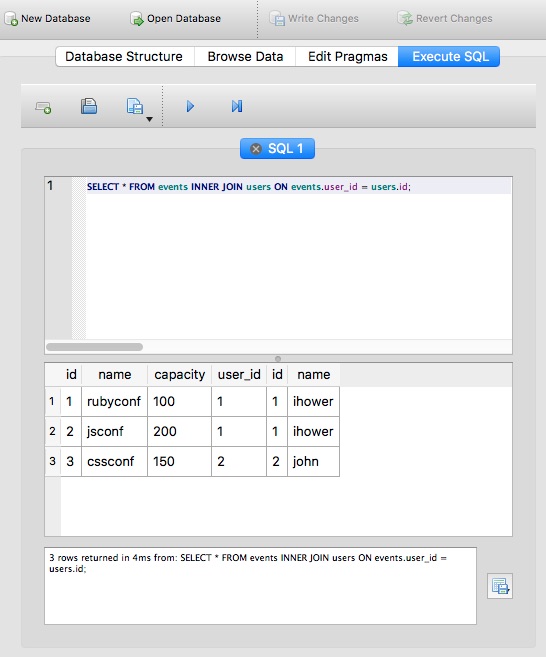
对应的 Rails 语法是 User.joins(:events) 。
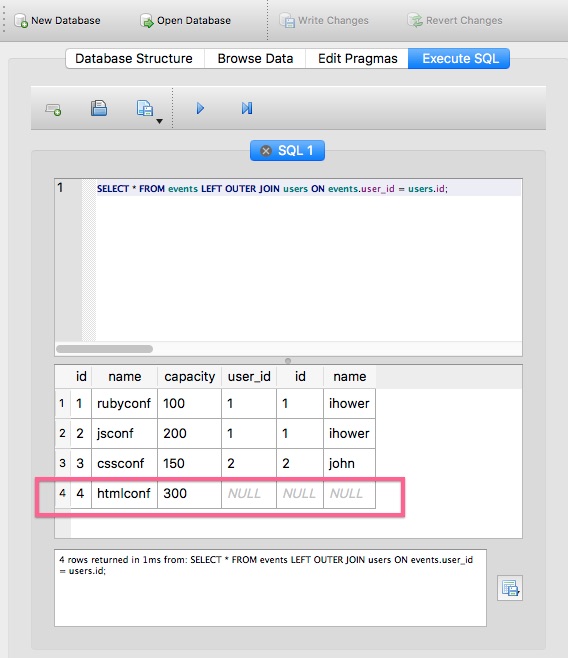
Outer Join(合并两张 tables,接不起来就填 NULL)
这里我们介绍 Left Outer Join 。
1 | # 取出所有活动,以及该活动的参与者资料(包括没有参与者的活动) |
结果如图:
AS 语法
因为有多张 tables 在 SQL 时,column 最好加上 table name 当作 prefix(前缀) (特别是有重复的 column name 时,在 WHERE 条件里可能会无法判断),或者可以 加上别名 AS。
例如:
1 | SELECT events.id AS event_id, events.capacity AS ec, events.name FROM events INNER JOIN users ON events.user_id = users.id WHERE ec=100; |
Rails 的 includes 原理
Rails ActiveRecord 的 includes 方法(当没有 WHERE 过滤条件时)则采用另一种 SQL 策略来作 Outer joining。
例如 Event.includes(:user) 这个 Rails 语法,实际上的 SQL 是:
1 | SELECT * FROM events; |
SQL Joins 图表
更多的关系可以参考下表:(详细戳 Visual Representation of SQL Joins)
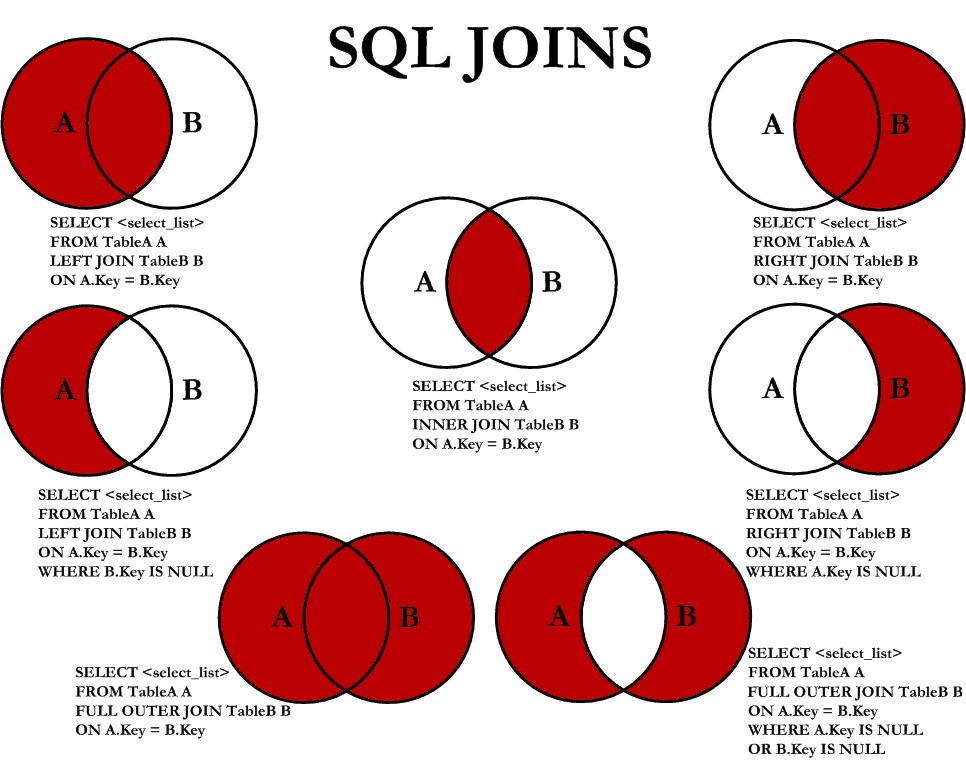
下图更清楚说明不同 Join 差别:(详细戳 SQL Joins Better)
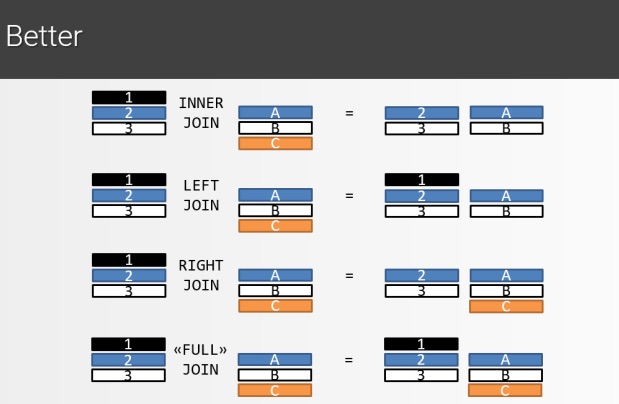
Functions
数据库也有提供一些 Function 可以用在 SQL 里面:
Aggregations (计算)
(加上 AS 别名比较好识别处理)
1 | # 数量 |
对应的 Rails 语法是 Event.count
1 | # 最小和最大值 |
对应的 Rails 语法是 Event.minimum(:capacity) 和 Event.maximum(:capacity)
1 | # 总和 |
对应的 Rails 语法是 Event.sum(:capacity)
1 | # 平均 |
对应的 Rails 语法是 Event.average(:capacity)
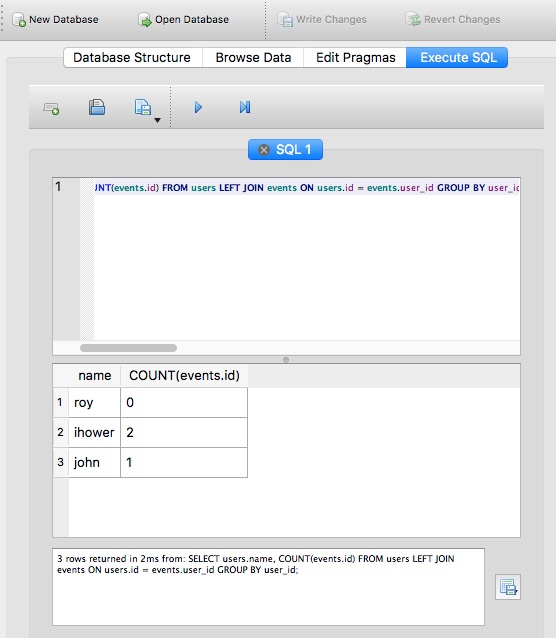
GROUP BY (分类)
GROUP BY 功能主要用来搭配上述 aggregating 来使用,例如请回答这个问题:计算每个 user 有多少 events?
让我们试试看:
1 | SELECT user_id, COUNT(*) FROM events; |
DISTINCT (去重)
1 | SELECT DISTINCT(user_id) FROM events; |
其他
数据库还提供其他函数,例如 SQLite 的 Useful Functions、 Date And Time Functions 等。
不过通常比较少用,因为我们偏好取出数据后,交由 Ruby 处理。
为何用高级操作
回头想想看为什么需要 Join 语法。SQL 的 Join 语法对新手比较困难,没办法完全掌握。很多时候我们在 Rails 先将需要的数据取出来,然后用 Ruby 进行过滤跟组合似乎也可达成目标,为什么需要用很复杂的 SQL Joining 语法?
主要的原因是 查询速度 和 内存空间 。数据库是一套针对 SQL 优化非常快速的软件,可以用远比 Ruby 高效的方式来取出数据。如果全部的数据都拿出来用 Ruby 处理,很可能内存不够。例如:请回答去年第三季所有商品的销售额,并根据分类计算总额。去年一整年的销售可能上百万笔数据,如果要逐笔捞出用 Ruby 处理,效能会非常低。这时候就必须用 SQL 精准地捞出想要的数据。
下一节我们来介绍 数据库如何设计。
Head First SQL(一) :数据库 概念初识。
Head First SQL(二) :关系型数据库 的特性。
Head First SQL(三) :SQL(Structured Query Language) 语言。
Head First SQL(四) :数据库如何设计。


